新春快樂!端傳媒新聞不停歇,你正在閱讀的即時新聞能夠免費呈現,全因有會員訂閱的支持,邀請你今天就成為其中一員。新春限時特惠:暢讀會員首年只要 8 折,即可暢讀全站深度內容;尊享會員首年 65 折,還贈送《華爾街日報》全語種會籍。立即登入訂閱會員,支持華語獨立新聞。
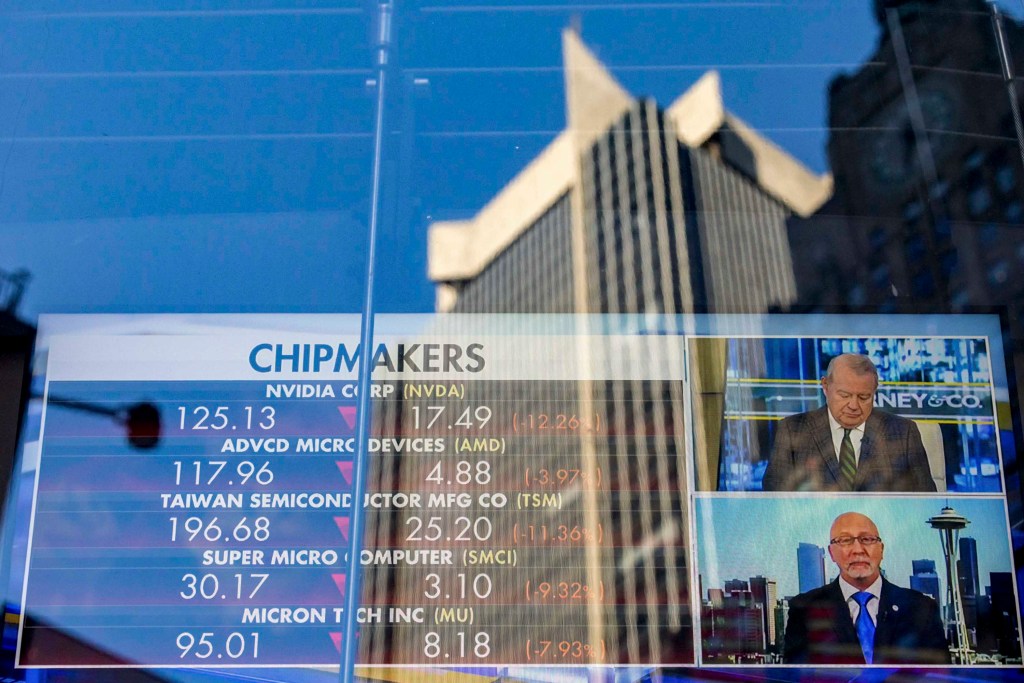
1月27日,美國主要科技股市出現大幅拋售,開盤縮水超1萬億美元,納斯達克指數收跌3.07%。多家AI科技龍頭公司均錄得史上最高跌幅之一,英偉達股價更重創16.86%,市值蒸發5890億美元,是該AI龍頭公司自COVID-19疫情初期2020年3月16日以來的最差表現。
雖然其後華爾街再度企穩,英偉達更在次日收復不少股價,但這場股市震盪,讓中國AI模型「DeepSeek」成為了全球焦點。普遍認為其性能達到世界先進水平,而開發成本則遠低於美國的AI巨頭,因而引發對整個AI產業盈利模式和預期的質疑。
引起熱議的是DeepSeek新近發佈的兩款人工智能模型。2024年12月,DeepSeek發佈V3模型評測成績超越Qwen2.5-72B(阿里自研大模型)和Llama 3.1-405B(Meta自研大模型)等開源模型,並能與GPT-4o、Claude 3.5-Sonnet(Anthropic自研大模型)等閉源模型相抗衡。
在V3的突破基礎上,2025年1月20日,DeepSeek又發布並開源了DeepSeek-R1模型。在多方測評中,該模型在數學、編程和自然語言推理方面與加州OpenAI領先的O1模型匹敵。根據一項熱門排名,DeepSeek的AI模型已跻身全球前十。隨後,市場對DeepSeek的評價一路走高,其更在蘋果App Store登頂,在美國地區免費應用程式下載排行榜,壓過了最熱門的ChatGPT。
DeepSeek不但性能表現令人驚嘆,其低成本和高效訓練模式也引人重視。DeepSeek此前曾表示,V3模型的訓練基於2048塊英偉達H800型GPU(針對中國大陸市場的低配版GPU)集群上運行55天完成,訓練耗資557.6萬美元,成本效益令人驚訝。
雖然R-1模型的訓練時間仍未有詳盡披露,但「DeepSeek用遠低於ChatGPT的成本達到相同效果」的說法已經開始廣為流傳。
在科技界,DeepSeek引起算法和訓練效能的比較,以及延伸討論開源是否比閉環更鼓勵創新。在政治層面,DeepSeek顛覆中美技術競賽的認知,輿論一方面關注中國人工智能發展是否已「彎道超車」,另一方面亦關注美國科技封鎖政策是否失效,甚至倒逼中國在人工智能更加進取和靈活發展。
然而最重要的衝擊反映在資本市場層面,DeepSeek以開源、低價的定位挑戰人工智能相關股票高企的前提,即訓練大模型需要大量投入,包括堆疊算力和芯片。有分析稱,DeepSeek在次先進的AI芯片上以更低成本的方式訓練出有效的模型,令市場對英偉達一飛衝天的估值產生疑慮。
但DeepSeek是否會令美國AI熱潮出現「擠泡沫」的趨勢,目前仍然言之尚早。
另據英國《金融時報》報導,ChatGPT的開發者OpenAI在1月29日表示,其有證據顯示DeepSeek用ChatGPT模型幫助訓練。報導引述業界人士,指這種被稱為「蒸餾」的做法在小型AI公司訓練模型時「非常常見」,但或使其捲入知識產權爭端。
AI投資基金背景,DeepSeek上年掀降價戰
許多媒體稱DeepSeek為不知名公司,但DeepSeek及其創始人梁文鋒在中國國內並非寂寂無名。
據報道,梁文鋒1985年出生於廣東省湛江市,就讀於浙江大學電子信息工程專業,後獲得信息與通信工程碩士學位。
在2015年,梁文鋒成立了DeepSeek的母公司杭州幻方科技有限公司,致力於通過數學和人工智能進行量化投資。2021年,幻方的資產管理規模突破千億大關,被稱為中國量化私募領域的「四大天王」之一。但同年,因為業績波動,幻方量化關閉全部募集通道,並在12月底致歉投資者,稱「幻方業績的回撤達到歷史最大值,我們對此深感愧疚」。
2023年7月,梁文鋒創辦深度求索DeepSeek,據指團隊成員多為中國名牌大學畢業生。2024年5月,DeepSeek發布DeepSeek-V2模型,因其模型架構與平價一躍成名,價格僅為GPT-4 Turbo的百分之一,開啟了中國大陸的大模型價格戰。其後,智譜 AI、字節、阿里、百度、騰訊等主要大模型廠商迅速跟進,模型API調用價格一再壓低,甚至免費。

集中開源和研究,真實算力儲備成謎
綜合傳媒報道和分析,DeepSeek在中國人工智能業界的位置獨特,沒有急於商業化AI模型,更集中於研究和技術,以及開源和公開。
有業內人士表示,DeepSeek「有相對充裕的卡,沒有融資壓力,前面幾年只做模型不做產品,讓DeepSeek和其他國內大模型公司相比顯得更加單純、聚焦,能夠在工程技術和算法上有所突破。」
梁文鋒曾在少有的公開採訪中表示,過去多年中國公司習慣了拿別人的技術創新做應用變現,Deepseek的出發點不是趁機賺一筆,而是走到技術的前沿,去推動整個生態發展。梁文鋒強調,「中國AI和美國真實的gap(差距)是原創和模仿之差。如果這個不改變,中國永遠只能是追隨者,所以有些探索也是逃不掉的。」
與很多科技公司不同,Deepseek還選擇了開源模式,通過分享其底層代碼和訓練方法,促進其他研究者的合作與創新。主導Meta AI研究的首席科學家楊立昆(Yann Le Cun)認為,DeepSeek不是中國AI超越美國,而是開源模型超越專有模型。
亦有一些聲音認為,在美國對芯片算力的限制下,中國開發的AI就算當前能夠趕上,長期也可能因為芯片限制而面臨困境,因此開源也是儘快擴大影響力,在世界AI產業中佔領更多市場的策略。
DeepSeek的爆紅,源於有限资源的高效利用,但外界亦關注其芯片存量。在2024年的一個訪問中,梁文鋒表示,「我們面臨的問題從來不是錢,而是高階晶片被禁運。」
據報,DeepSeek是中國科技巨企業中唯一一家儲備萬張英偉達A100芯片的公司。而美國人工智能數據公司Scale AI創始人Alexandr Wang則稱,DeepSeek擁有大約5萬塊英偉達H100芯片,但因美國出口管制措施,他們不能公開談論。惟相關說法未獲得證實。
英偉達回應指,DeepSeek是AI領域的一項卓越進步,展示了如何利用測試時間縮放(Test Time Scaling)技術、廣泛可用的模型以及完全符合出口管制的計算資源來創建新型號。

特朗普稱讚,梁對總理稱芯片是限制
在中美AI競賽之際,Deepseek的崛起尤其令人關注。在1月26日,美國風險投資家Marc Andreessen在X上發帖表示,DeepSeek的R1模型是人工智能的「史普尼克時刻」,即是20世紀50年代末標前蘇聯衛星發射,開啟太空競賽的時刻。
在1月27日,美國總統特朗普稱,DeepSeek「為業界敲響警鐘,美國須極度專注應對競爭。」特朗普又稱讚,DeepSeek取得突破是一件好事,因為不必花費大量金錢來發展大模型。
早前,特朗普與軟銀和OpenAI等機構共同宣布投資5000億美元的「星門計畫」,旨在建設新一代AI基礎設施,鞏固美國在AI領域的領導地位。
在中國,DeepSeek創辦人梁文鋒在1月20日下午成為中國總理李強的座上賓,參加了中國國務院總理座談會。該會議是國務院就《政府工作報告(徵求意見稿)》的座談會,與會者是專家、企業家和教科文衛體等領域代表。
據報梁文鋒對李強表示,儘管中國企業正努力追趕,但美方限制先進芯片出口中國仍是瓶頸。
DeepSeek如日中天,中國是否在「彎道超車」引人熱議。對此,清華大學計算機系副教授劉知遠表示,「AGI新技術還在加速演進,未來發展路徑尚不明確。我們仍在追趕階段,已經不是望塵莫及,但也只能說是望其項背」,「在別人已經探索出來的路上跟隨快跑是相對容易的,接下來我們要面對一團未來迷霧。」
另外,DeepSeek亦引起美國安全方面的討論。一部分批評認為,在六四事件、台灣問題等方面,DeepSeek顯示出了中國政府的嚴格審查。還有一部分聲音則擔憂其開源特點會令中國對全球AI產業擁有巨大的影響力。
在接受CNBC訪問時,美國AI初創公司Perplexity首席執行官Aravind Srinivas表示,DeepSeek是非常創新的產物,反映出中國相關領域的技術成就,也以開源的姿態開始逼迫美國AI公司提高效率、改變思路。但他認為「如果整個美國AI生態系統都依賴於中國的開源模型,那將是非常危險的......人們曾質疑是否應該信任扎克伯格(祖克柏),但現在的問題是,我們是否應該信任中國?」他指DeepSeek雖開源,但或許也有一天「許可證會改變」。





評論區 0