
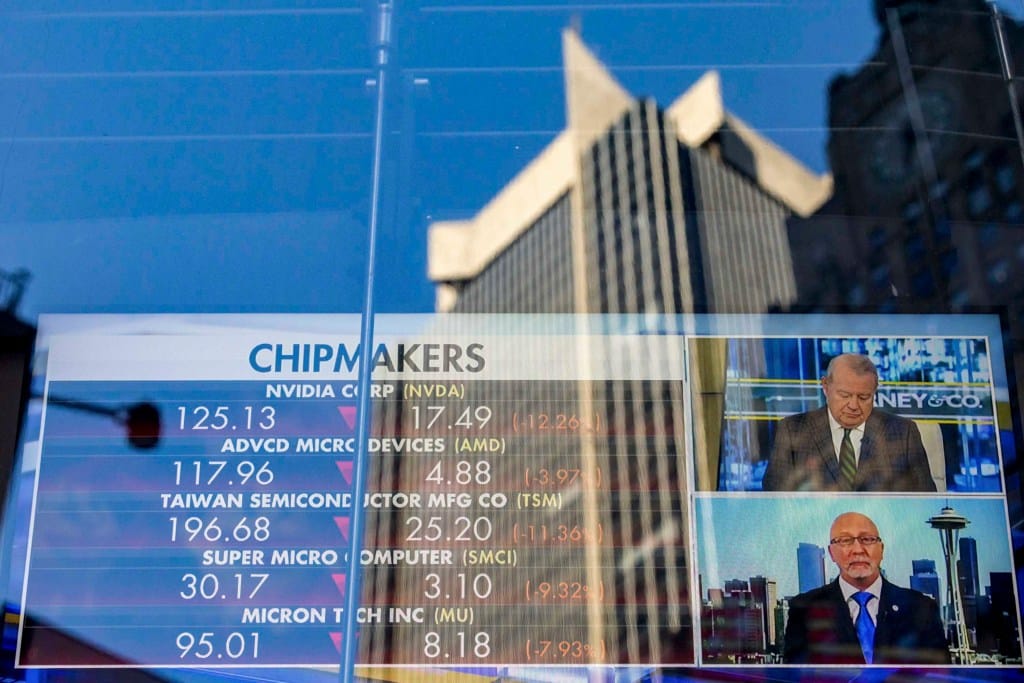
1月27日,美国主要科技股市出现大幅抛售,开盘缩水超1万亿美元,纳斯达克指数收跌3.07%。多家AI科技龙头公司均录得史上最高跌幅之一,英伟达股价更重创16.86%,市值蒸发5890亿美元,是该AI龙头公司自COVID-19疫情初期2020年3月16日以来的最差表现。
虽然其后华尔街再度企稳,英伟达更在次日收复不少股价,但这场股市震荡,让中国AI模型“DeepSeek”成为了全球焦点。普遍认为其性能达到世界先进水平,而开发成本则远低于美国的AI巨头,因而引发对整个AI产业盈利模式和预期的质疑。
引起热议的是DeepSeek新近发布的两款人工智能模型。2024年12月,DeepSeek发布V3模型评测成绩超越Qwen2.5-72B(阿里自研大模型)和Llama 3.1-405B(Meta自研大模型)等开源模型,并能与GPT-4o、Claude 3.5-Sonnet(Anthropic自研大模型)等闭源模型相抗衡。
在V3的突破基础上,2025年1月20日,DeepSeek又发布并开源了DeepSeek-R1模型。在多方测评中,该模型在数学、编程和自然语言推理方面与加州OpenAI领先的O1模型匹敌。根据一项热门排名,DeepSeek的AI模型已跻身全球前十。随后,市场对DeepSeek的评价一路走高,其更在苹果App Store登顶,在美国地区免费应用程式下载排行榜,压过了最热门的ChatGPT。
DeepSeek不但性能表现令人惊叹,其低成本和高效训练模式也引人重视。DeepSeek此前曾表示,V3模型的训练基于2048块英伟达H800型GPU(针对中国大陆市场的低配版GPU)集群上运行55天完成,训练耗资557.6万美元,成本效益令人惊讶。
虽然R-1模型的训练时间仍未有详尽披露,但“DeepSeek用远低于ChatGPT的成本达到相同效果”的说法已经开始广为流传。
在科技界,DeepSeek引起算法和训练效能的比较,以及延伸讨论开源是否比闭环更鼓励创新。在政治层面,DeepSeek颠覆中美技术竞赛的认知,舆论一方面关注中国人工智能发展是否已“弯道超车”,另一方面亦关注美国科技封锁政策是否失效,甚至倒逼中国在人工智能更加进取和灵活发展。
然而最重要的冲击反映在资本市场层面,DeepSeek以开源、低价的定位挑战人工智能相关股票高企的前提,即训练大模型需要大量投入,包括堆叠算力和芯片。有分析称,DeepSeek在次先进的AI芯片上以更低成本的方式训练出有效的模型,令市场对英伟达一飞冲天的估值产生疑虑。
但DeepSeek是否会令美国AI热潮出现“挤泡沫”的趋势,目前仍然言之尚早。
另据英国《金融时报》报导,ChatGPT的开发者OpenAI在1月29日表示,其有证据显示DeepSeek用ChatGPT模型帮助训练。报导引述业界人士,指这种被称为“蒸馏”的做法在小型AI公司训练模型时“非常常见”,但或使其卷入知识产权争端。
AI投资基金背景,DeepSeek上年掀降价战
许多媒体称DeepSeek为不知名公司,但DeepSeek及其创始人梁文锋在中国国内并非寂寂无名。
据报道,梁文锋1985年出生于广东省湛江市,就读于浙江大学电子信息工程专业,后获得信息与通信工程硕士学位。
在2015年,梁文锋成立了DeepSeek的母公司杭州幻方科技有限公司,致力于通过数学和人工智能进行量化投资。2021年,幻方的资产管理规模突破千亿大关,被称为中国量化私募领域的“四大天王”之一。但同年,因为业绩波动,幻方量化关闭全部募集通道,并在12月底致歉投资者,称“幻方业绩的回撤达到历史最大值,我们对此深感愧疚”。
2023年7月,梁文锋创办深度求索DeepSeek,据指团队成员多为中国名牌大学毕业生。2024年5月,DeepSeek发布DeepSeek-V2模型,因其模型架构与平价一跃成名,价格仅为GPT-4 Turbo的百分之一,开启了中国大陆的大模型价格战。其后,智谱 AI、字节、阿里、百度、腾讯等主要大模型厂商迅速跟进,模型API调用价格一再压低,甚至免费。
集中开源和研究,真实算力储备成谜
综合传媒报道和分析,DeepSeek在中国人工智能业界的位置独特,没有急于商业化AI模型,更集中于研究和技术,以及开源和公开。
有业内人士表示,DeepSeek“有相对充裕的卡,没有融资压力,前面几年只做模型不做产品,让DeepSeek和其他国内大模型公司相比显得更加单纯、聚焦,能够在工程技术和算法上有所突破。”
梁文锋曾在少有的公开采访中表示,过去多年中国公司习惯了拿别人的技术创新做应用变现,Deepseek的出发点不是趁机赚一笔,而是走到技术的前沿,去推动整个生态发展。梁文锋强调,“中国AI和美国真实的gap(差距)是原创和模仿之差。如果这个不改变,中国永远只能是追随者,所以有些探索也是逃不掉的。”
与很多科技公司不同,Deepseek还选择了开源模式,通过分享其底层代码和训练方法,促进其他研究者的合作与创新。主导Meta AI研究的首席科学家杨立昆(Yann Le Cun)认为,DeepSeek不是中国AI超越美国,而是开源模型超越专有模型。
亦有一些声音认为,在美国对芯片算力的限制下,中国开发的AI就算当前能够赶上,长期也可能因为芯片限制而面临困境,因此开源也是尽快扩大影响力,在世界AI产业中占领更多市场的策略。
DeepSeek的爆红,源于有限资源的高效利用,但外界亦关注其芯片存量。在2024年的一个访问中,梁文锋表示,“我们面临的问题从来不是钱,而是高阶晶片被禁运。”
据报,DeepSeek是中国科技巨企业中唯一一家储备万张英伟达A100芯片的公司。而美国人工智能数据公司Scale AI创始人Alexandr Wang则称,DeepSeek拥有大约5万块英伟达H100芯片,但因美国出口管制措施,他们不能公开谈论。惟相关说法未获得证实。
英伟达回应指,DeepSeek是AI领域的一项卓越进步,展示了如何利用测试时间缩放(Test Time Scaling)技术、广泛可用的模型以及完全符合出口管制的计算资源来创建新型号。
特朗普称赞,梁对总理称芯片是限制
在中美AI竞赛之际,Deepseek的崛起尤其令人关注。在1月26日,美国风险投资家Marc Andreessen在X上发帖表示,DeepSeek的R1模型是人工智能的“史普尼克时刻”,即是20世纪50年代末标前苏联卫星发射,开启太空竞赛的时刻。
在1月27日,美国总统特朗普称,DeepSeek“为业界敲响警钟,美国须极度专注应对竞争。”特朗普又称赞,DeepSeek取得突破是一件好事,因为不必花费大量金钱来发展大模型。
早前,特朗普与软银和OpenAI等机构共同宣布投资5000亿美元的“星门计划”,旨在建设新一代AI基础设施,巩固美国在AI领域的领导地位。
在中国,DeepSeek创办人梁文锋在1月20日下午成为中国总理李强的座上宾,参加了中国国务院总理座谈会。该会议是国务院就《政府工作报告(征求意见稿)》的座谈会,与会者是专家、企业家和教科文卫体等领域代表。
据报梁文锋对李强表示,尽管中国企业正努力追赶,但美方限制先进芯片出口中国仍是瓶颈。
DeepSeek如日中天,中国是否在“弯道超车”引人热议。对此,清华大学计算机系副教授刘知远表示,“AGI新技术还在加速演进,未来发展路径尚不明确。我们仍在追赶阶段,已经不是望尘莫及,但也只能说是望其项背”,“在别人已经探索出来的路上跟随快跑是相对容易的,接下来我们要面对一团未来迷雾。”
另外,DeepSeek亦引起美国安全方面的讨论。一部分批评认为,在六四事件、台湾问题等方面,DeepSeek显示出了中国政府的严格审查。还有一部分声音则担忧其开源特点会令中国对全球AI产业拥有巨大的影响力。
在接受CNBC访问时,美国AI初创公司Perplexity首席执行官Aravind Srinivas表示,DeepSeek是非常创新的产物,反映出中国相关领域的技术成就,也以开源的姿态开始逼迫美国AI公司提高效率、改变思路。但他认为“如果整个美国AI生态系统都依赖于中国的开源模型,那将是非常危险的......人们曾质疑是否应该信任扎克伯格,但现在的问题是,我们是否应该信任中国?”他指DeepSeek虽开源,但或许也有一天“许可证会改变”。



